NLP - RNNs, Transformers, Hugging Face¶
In this notebook, we will be understanding and delving more deeply into NLP. Currently, NLP is the most popular application of deep learning. All Large Language Models (LLMs) currently operate based on the transformer architecture to provide generative capabilities.
We will try to make a NLP classification model that can identify Charles Dickens' writings.
This notebook is based off of module 4 of Fast AI's on NLP.
Language Models¶
A language model is a model that is trained to predict the next word in a text based on the previous words. A language model uses something called self-supervised training to achieve this. Without external labels, it can find labels within the text it needs to evaluate. To achieve this, our language model needs to develop a certain understanding of the language. This means that for our applications, our language model needs to understand the English language, the French language, the German language, etc.
An example of an application development process is the IMDb review classifier. We will use a language model that was trained on Wikipedia data. Unfortunately, this model might not be entirely suitable for IMDb review English. Wikipedia articles are usually written in a different style and format from an IMDb review. In order to get accurate classifications, we ought to fine-tune our model on IMDb English. From that fine-tuned model, we can then work on developing a classification model for IMDb movie reviews that will be very accurate.
The preceding process is called the Universal Language Model Fine-Tuning Process (ULMFit).
Recurrent Neural Networks - RNNs¶
Recurrent Neural Networks (RNNS) are a type of neural network architecture trained on sequential or time series data that are used to make machine learning models that can make sequential predictions using previous sequence elements as inputs for the predictions. RNNs use a hidden state that helps keep track of previous inputs. This is the recurrent part of the RNN.
RNNS use a encoder-decoder model. This model is best explained by the following image:
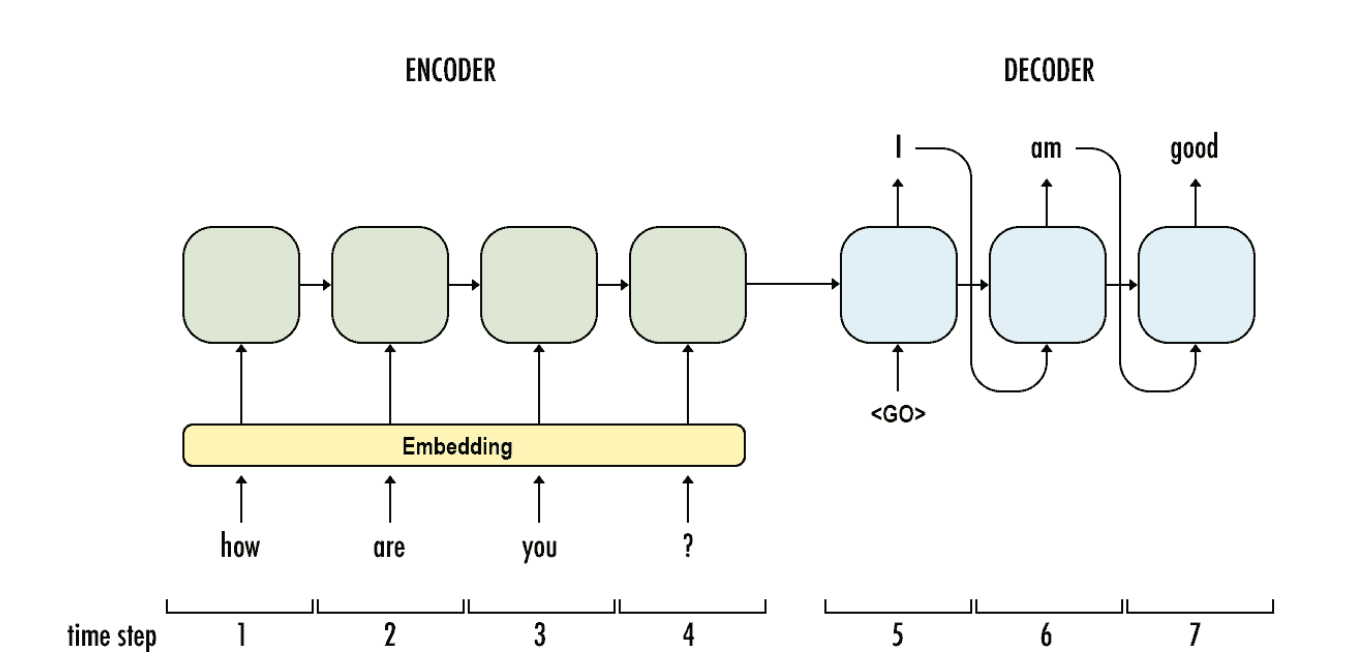
For more information:
Transformers¶
Transformers are a type of neural network architecture that is very capable of processing natural language. Unlike RNNs, transformers do not use any recurrence or have hidden states. This means they do not operate sequentially (ie, they do not need to go through each input one at a time). They use something called self-attention. Self-attention allows the model to weigh the importance of different input tokens when making predictions. Transformers consist of encoder and decoder layers, employing multi-head self-attention mechanisms and feedback neural networks. Thanks to these features, they are able to parallelize their operations and are faster.
Here is an image illustrating the transformer model.
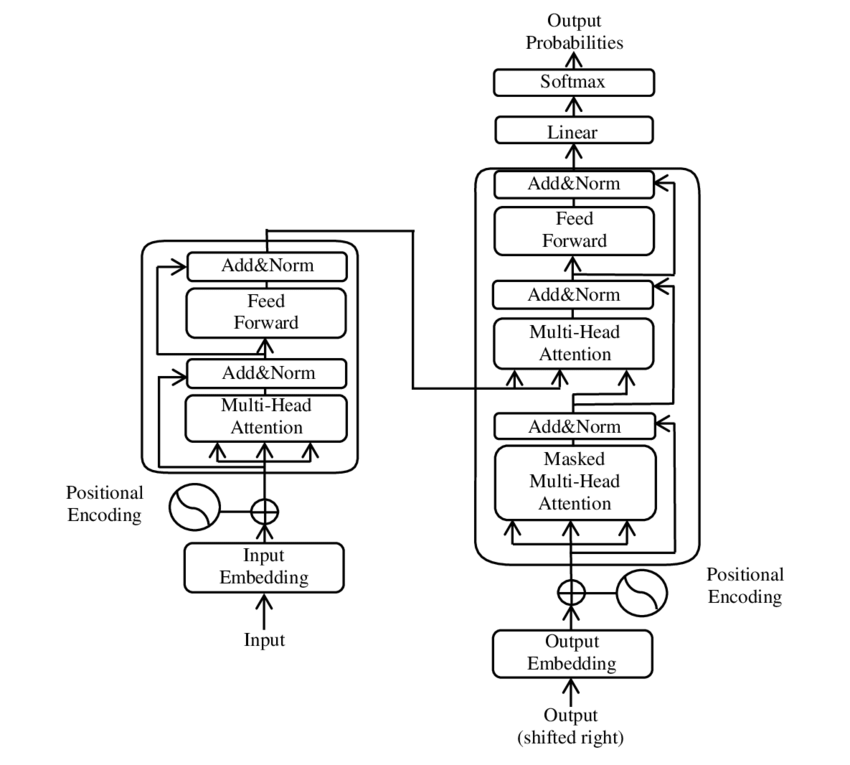
The transformer model was layed out in the 2017 seminal paper Attention Is All You Need.
Tokenization and Numericalization¶
Our neural networks need to take in numbers as their inputs. We need to convert our sentences into numbers, there are two steps:
- Tokenization: we split text up into tokens
- Numericalization: convert each token into a number
This process is model dependent. Each model will have a tokenizer associated with it. We'll see when developing our Dickens classifier.
model_nm = "ProsusAI/finbert"
AutoTokenizer is a HuggingFace Transformers class that allows us to get our tokenizer function.
from transformers import AutoTokenizer
tokz = AutoTokenizer.from_pretrained(model_nm)
tokz.tokenize("Hi! I am Sami")
Our Dataset¶
from datasets import load_dataset
dickens_ds = load_dataset("GuillermoTBB/charles-dickens-text-classification")
dickens_ds
train, test = dickens_ds['train'], dickens_ds['test']
train_df = train.to_pandas()
train_df
def tok_func(ds):
return tokz(ds['text'])
tok_ds = train.map(tok_func, batched=True)
tok_ds
tok_ds_df = tok_ds.to_pandas()
tok_ds_df
import numpy as np
from numpy.random import normal, seed, uniform
np.random.seed(42)
dataloaders = tok_ds.train_test_split(0.25, seed=42)
dataloaders = dataloaders.rename_column('label',"labels")
dataloaders.set_format(
type="torch",
columns=["input_ids", "attention_mask", "labels"]
)
dataloaders
Training our model¶
from transformers import TrainingArguments
bs = 4
epochs = 2
learning_rate = 0.1
args = TrainingArguments(
output_dir="dickens-model",
learning_rate=learning_rate,
per_device_train_batch_size=bs,
per_device_eval_batch_size=bs*2,
num_train_epochs=epochs,
weight_decay=0.01,
eval_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
push_to_hub=False,
)
Defining our metrics¶
We need to define a function to evaluate our model.
def accuracy(prediction, label):
pred_classes = np.argmax(prediction, axis=1)
return np.mean(pred_classes == label)
def metrics(dataset):
return {'accuracy': accuracy(*dataset)}
Training our model¶
The Transformers library provides some APIs to facilitate training.
from transformers import AutoConfig, AutoModelForSequenceClassification, Trainer
config = AutoConfig.from_pretrained(
model_nm,
num_labels=2,
id2label={0:"not_dickens",1:"dickens"},
label2id={"not_dickens":0,"dickens":1},)
model = AutoModelForSequenceClassification.from_config(config)
trainer = Trainer(model=model,
args=args,
train_dataset=dataloaders['train'],
eval_dataset=dataloaders['test'],
tokenizer=tokz,
compute_metrics=metrics
)
trainer.train()
test = test.map(tok_func, batched=True)
test
preds = trainer.predict(test)
preds
model = AutoModelForSequenceClassification.from_pretrained("./dickens-model/checkpoint-165")
print("Head bias:", model.classifier.bias.data)
# using the pipeline API -- a general inference function
from transformers import pipeline
classifier = pipeline(task="text-classification", model="./dickens-model/checkpoint-165", tokenizer="./dickens-model/checkpoint-165", return_all_scores=True)
classifier("Joe was evidently made uncomfortable by what he supposed to be my loss of appetite, and took a thoughtful bite out of his slice, which he didn’t seem to enjoy. He turned it about in his mouth much longer than usual, pondering over it a good deal, and after all gulped it down like a pill. He was about to take another bite, and had just got his head on one side for a good purchase on it, when his eye fell on me, and he saw that my bread and butter was gone.")